Data Science Lab was established in 2017 to cater the challenges of current age which may be termed as the era of “data big bang”. Driven by the internet economy, mobile phone, cheaper hardware and the Internet of Things (IoT), the user and other sensory devices are continuously generating a lot of data. As data size increases, the demand for multi scale approaches in transforming data to knowledge also becomes very important. Research in DSL involves the design of intelligent algorithms and development of decision-making models to form risk management systems and process modeling systems. Interpreting data and visualizing it to define patterns and extract knowledge can help businesses to compete with other competitors. The lab focuses on both the structured and unstructured data analytics for clustering, classification, and association rule mining to identify trends and make useful predictions.
The lab is currently focused on developing a knowledge extraction framework which can be applied to multiple types of textual data including news articles, scientific literature, social media, and police investigation reports. The lab aims to bring together researchers, industry experts, and students to provide a platform for flourishing the field of data science in Pakistan.
Lab Objective’s
- Finding new approaches for data collection, integration, and data/information sharing technologies
- Develop new statistical and mathematical algorithms, prediction method, modeling methods, compaction schemes
- Seeking a new way to derive useful, reliable, and verifiable information from big and complex data sets, by using advances in information processing, integration, machine learning, data mining, compression, and visualization of data
- Focus on data science research and education that address the challenges of large data sets, high consumption rates, short analysis time windows, different content and media types, and contradicting, incorrect, and missing information
- Develop scalable data processing systems, and showcase their solutions to challenging real-world use cases of relevance to science, industry, and society
1- SETMOKE API
Urdu has witnessed the development of significant applications such as email spam detection, genre identification, product review analysis, news categorization, fake news detection, text classification and many more Urdu is considered a linguistically rich and morphologically complex language, thus, state of the art natural language processing APIs like Gensim, SPacy, NLTK, CoreNLP can not process Urdu text at all
SETMOKE API is a language processing toolkit based on machine and deep learning which provides multifarious modules to manage and process Urdu text. It may help numerous researchers and practitioners to develop smart applications. Contribution of Frame works

SETMOKE API Provides Following Modules
1- Pre-processing
2- Urdu Text Classification
3- Urdu Text Summarization
4- Urdu Stemmer
5- Urdu Question Classification
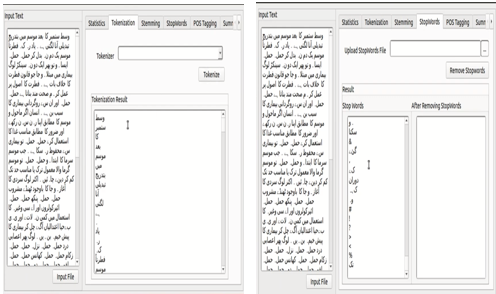
Preprocessing of text enables the better extraction of non-trivial knowledge from unstructured text Preprocessing pipeline comprises of tokenization, stemming, pos tagging, and named entity recognition enable the extraction of significant information from unstructured text. SETMOKE API preprocessing module provides robust algorithms for tokenization, stemming, pos tagging and named entity recognition which are considered indispensable for sentiment analysis, and recommendation systems
Pre-Processing Interface
Urdu Text Classification
Text classification plays an important role for the development of diverse applications such as email spam detection, gender identification, product review analysis, news categorization, and fake news detection. SETMOKE API text classification module employ ten filter based feature selection methods, two feature representation approaches, and two machine learning classifiers to effectively classify Urdu text in one of the predefined categories.
Urdu Text Classification Methodology

Urdu Text Classification Interface

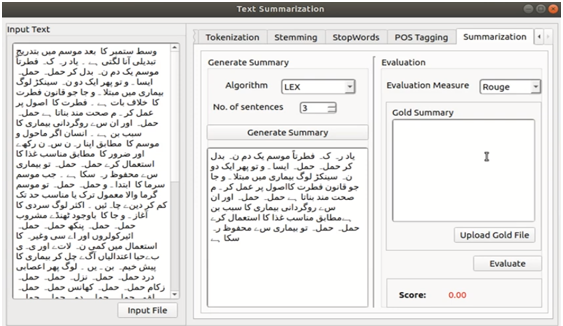
Urdu Text Summarization
Automatic text summarization is being extensively used for various renowned languages (English, Chinese) in order generate precise and fluent summaries. SETMOKE APIs text summarization module exploits five state of the art extractive summarization methods in order to generate an effective summary of single document
Urdu Text Summarization Methodology

Urdu Text Summarization Interface
Urdu Steemer
Stemming plays a vital role to alleviate data sparsity problems by converting inflected forms of words to their base forms, thus, reducing dimensionality of data up to great extent SETMOKE Urdu stemmer works as follows:

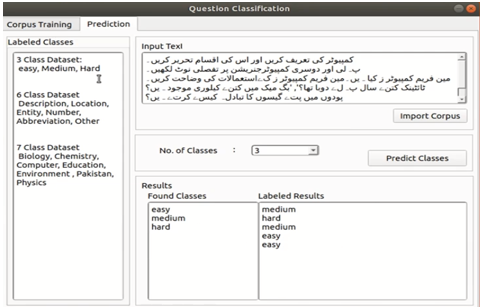
Urdu Question Classification
Question classification refers to the process of classifying questions into predefined categories. It plays an effective role in the performance of information retrieval. With the help of question classification, the lookup span of the search engine can be reduced upto great extent through question classification as search engine has to search the answer of the provided query only in certain domain and context. SETMOKE question classification module classify questions into three, six, and seven classes based on difficulty, general properties, and subjectivity
Methodology of Urdu Question Classification

Urdu Question Classification Interface
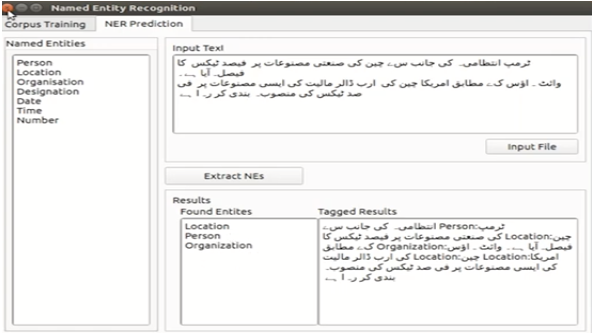
Named Entity Recognition
Named entity recognition plays a vital role in the development of numerous applications based on speech recognition, information retrieval, and machine translation. SETMOKE APIs named entity recognition module is capable to detect person name, organization, location, date, time, number,
and designation from Urdu text.
Methodology of NER

NER Interface
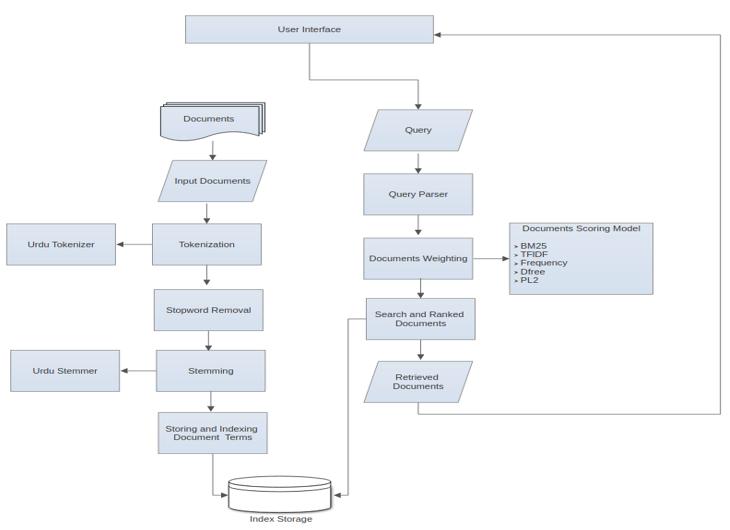
Information Retrieval
Information retrieval (IR) refers to the process of finding and acquiring certain data or documents from large collections against particular user query IR has revolutionized search engines by providing robust methodologies to extract most relevant documen ts or information from unstructured texts SETMOKE API IR module is capable to index, store and query a document based on relevancy. It implements several similarity measures such as BM25,TFIDF, Frequency, Dfree and PL2.
Methodology of IR
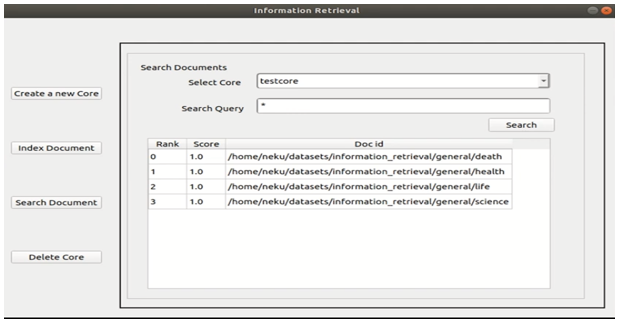
Information Retrieval Interface
Urdu Sentiment Analysis
Sentiment analysis or opinion mining is all about identifying people perceptions regarding the certain organization, person, place, product or service. Customers perceptions and feedback are usually acquired through focus groups, surveys, observation, and some other pretty labor intensive methods SETMOKE sentiment analysis employ deep learning models and an existing Urdu sentiment dictionary comprising of 4000 positive and 2000 negative expressions to correctly classify sentiments. We also extend the Urdu sentiment dictionary with 4000 neutral expressions in order to better classify sentiments expressed in Nastaleeq Urdu.
Methodology of Urdu Sentiment Analysis
Urdu Sentiment Analysis Interface

Datasets and Results (As per Need)
Contribution of Datasets
Urdu Stemmer This dataset has 4162 base words and 9743 words with possible variations of the base words.Accuracy is 97 % Urdu Text Classification Statistics of DSL and CLE dataset
Results of Urdu Text Classification
1- DSL Dataset Results Results of Text Classification CLE dataset Results
2- Urdu Text Summarization Dataset and Statistics
3- Results of Urdu Text Summarization
4- Urdu Question Classification
Subjectivity Based E-Learning Dataset Classes and Number of Questions
Biology : 274
Chemistry: 52
Computer: 166
Education: 124
Environment: 13
Pakistan Studies: 39
Physics: 137
Algorithm : CNN-based Model
Accuracy : N/A
Difficulty based E-Learning Dataset
Classes and Number of Questions
Hard : 274
Medium: 52
Easy: 166
General Urdu Question Classification dataset
Description : 801
Entity : 1004
Abbreviation : 35
Number : 408
Location : 193
Other : 76
Urdu Named Entity (Recognition Available Tags)
Person
Location
Organization
Designation
Date
Time
Number
Algorithm : Bidirectional-LSTM
Accuracy : 93.35%
Dataset Statistics
Total Documents: 633
Total Sentences: 3232
Total Words: 109816
Total unique words : 12527
Words with no Tags: 88.75%
Location tags: 1.92%
Person tags: 3.44%
Time tags: 0.36%
Organization tags: 1.48%
Number tags: 2.09%
Designation tags: 0.66%
DATE tags: 1.3%
Nastaliq Urdu Sentiment Classes and Training Words
Positive: 2633 Words
Negative: 4754 Words
Neutral: 2000 Words
Total 109 sentences for testing
Positive: 51 Sentences
Negative: 48 Sentences
Neutral: 10 Sentences
Accuracy : 97%
Roman Urdu Sentiment Analysis
Classes
Positive
Negative
Neutral
Total Documents: 12099
Training: 8711
Validation : 2178
Testing : 1210
Accuracy : 71.4%
Urdu Information Retrieval
We used 500 documents from different classes such as agriculture,business, entertainment, news and sports etc. We used 30 Queries relevant to
document classes to make Gold Standard dataset.
Applications of:
1- SETMOKE Spam Complaints Filtering System
2- Criminal Case Log Aggregation & Summarization
3- Ontology based Urdu Car Advertisement Search Engine
- A survey of ontology learning techniques and applications, Muhammad Nabeel Asim, Muhammad Wasim, Muhammad Usman Ghani Khan, Waqar Mahmood, Hafiza Mahnoor Abbasi, Database, Volume 2018, 2018, bay101
- Improved biomedical term selection in pseudo relevance feedback, Muhammad Nabeel Asim, Muhammad Wasim, Usman Ghani Khan M, Mahmood W.Database (Oxford). ;2018:bay056. doi:10.1093/database/bay056.
- Multi-label Biomedical Question Classification for Lexical Answer Type Prediction, Muhammad Wasim., Muhammad Nabeel Asim, Khan, M. U. G., & Mahmood, W. (2019). Journal of biomedical informatics, 103143.
- Multi-Label Question Classification for Factoid and List Type Questions in Biomedical Question Answering.Muhammad Wasim, Waqar Mahmood, Muhammad Nabeel Asim, & Khan, M. U. (2019). IEEE Access, 7, 3882-3896.
- The Use of Ontology in Retrieval: A Study on Textual, Multilingual, and Multimedia Retrieval.,Muhammad Nabeel Asim, Wasim, M., Khan, M. U. G., Mahmood, N., & Waqar Mahmood(2019). IEEE Access, 7, 21662-21686.
- A Robust Hybrid Approach for Textual Document Classification Muhammad Nabeel Asim, Muhammad Usman Ghani Khan, Sheraz Ahmed, Andreas Dengel and Muhammad Imran Malik at International Conference on Document Analysis and Recognition (ICDAR).
- Two Stream Deep Network for Document Image Classification Muhammad Nabeel Asim, Khizar Razzaque, Sheraz Ahmed, Muhammad Usman Ghani Khan, Andreas Dengel and Muhammad Imran Malik at International Conference on Document Analysis and Recognition (ICDAR).
Submitted:
- A review of machine and deep learning based Ontology learning tools.
- Performance comparison of machine and deep learning based methodologies for Urdu text document classification.
On-going
Named entity Recognition
Multi-label Text Classification
Stemming